什么是存储基金 Endowment?


作者:Gerry Wang
在 #Arweave 的核心机制中,有一个非常重要的概念与部件,就是存储基金 #Endowment。笔者在此前一篇文章中《Arweave 的 $AR 通货紧缩了吗?》已经有所描述。本文将对其进行更加详细的介绍。
在 Arweave 的激励模型中,要求数据上传者为永久存储支付一笔交易部署费,并向网络的存储基金(Storage Endowment)以 $AR 来提供用于永存的预缴费用。这个基金充当了一个支付水龙头的角色,随着时间的推移,矿工在提供数据集的复制证明时,将通过这个水龙头来获得支付。由于存储成本是不断下降的,所有维护一条数据所需从基金中获得的支付金额也会随之自动而减少。
存储价格
用户提前为存储 20 份副本 200 年而支付的费用,是基于当前的成本计算的。Arweave 协议的优势之处在于它提供了一个非常科学的无需信任的机制来确定从矿工获取存储空间的价格。在具有特定难度 d_B 的单个区块 B 的时期内,网络中的分区估计数量由上一篇文章中的公式可以计算得出:
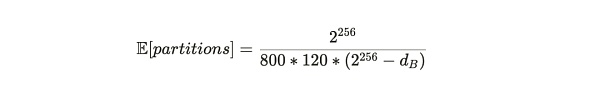
将这个表达式乘以分区(Partition)大小,可以计算出在区块 B 时刻 Arweave 全网当前的总存储量:

作为奖励发放给矿工的 $AR 数量和区块的难度可以用来估计存储获取成本 — 在区块 B 时刻,为 1 GB 服务 1 分钟支付的费用:
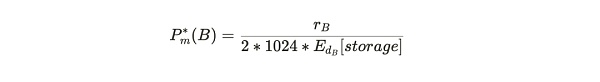
其中:
P_m^(B) = 在区块 B 时刻,存储 1 GB 数据 1 分钟的估计成本
r_B = 区块 B 的所有回报
公式注解:全网存储总数据量以 TB 计算,所以需要乘以 1024 将其转为 GB 单位;分母中的「2」 是一个区块 2 分钟的意思,所以需要除以 2 来将其变为每分钟的的估算成本。
使用单个区块周期来估计存储价格会有很高的不稳定性,这是由于收集到的交易部署费和难度调整算法之间的差异所致。因此,在实际操作中,网络会记录大量区块上的难度和释放的奖励。这些记录被网络用来准确计算在区块前 6 周内从矿工那里获得的存储获取成本:
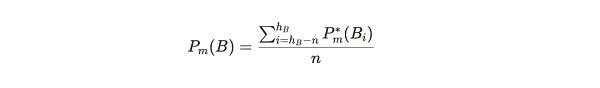
其中:
P_m(B) = 在 6 周时间内计算的 1 GB 1 分钟的平均存储获取成本。
h_B = 区块 B 的高度。
n = 6 周内区块的数量( 30247*6 = 30,240 )。
利用这些计算,网络可以准确估算出一个区块周期(约 2 分钟)内 1 GB 存储的获取成本:

根据这个公式,协议计算任何数据 D 的 20 份副本在 200 年内的当前价格如下:
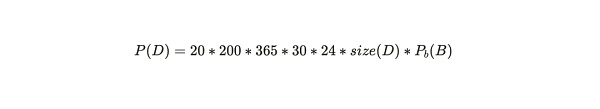
这是作为预先贡献向用户收取的价格,用于存储基金。随着时间的推移,矿工在证明了他们存储了网络数据集后,将从基金中获得支付,支付计算如下:
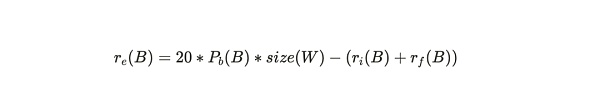
其中:
r_e(B) = 在区块 B 从基金中的提取
r_i(B) = 在区块 B 中释放的通货膨胀奖励
r_f(B) = 在区块 B 中接受的交易的交易部署费
P_B(B) = 在区块 B 时刻,存储 1 GB 数据一个区块周期的估计成本
W = 在区块 B 时刻,存储在 Arweave 上的所有数据集
这个公式的意思是当总存储成本比获得的区块奖励大时,将会从基金中提取费用用于补贴矿工。但从不前的数据看,这个公式的结果为负数,所有不仅不会从存储基金中提取费用,还要将一部分费用存入基金中。
通货紧缩与基金价值
每当数据被上传时,Arweave 网络就会将流通中的相应数量代币,移至用于支付随时间而累积的数据存储费用的基金中(Endowment)。基金的存储购买力是有弹性的,它随着提交的数据量、数据存储成本和代币价值的变化而变化。
基金价值变化的主要驱动因素之一是存储成本的降低而导致存储购买力以相应比例增加,从而导致未来需要从基金中释放的代币数量减少。我们将在一个时间周期中实际存储一单位数据的总成本下降速率称为 kryder+ 。这个速率包括硬件价格、电力成本和数据存储相关运营成本的变化。
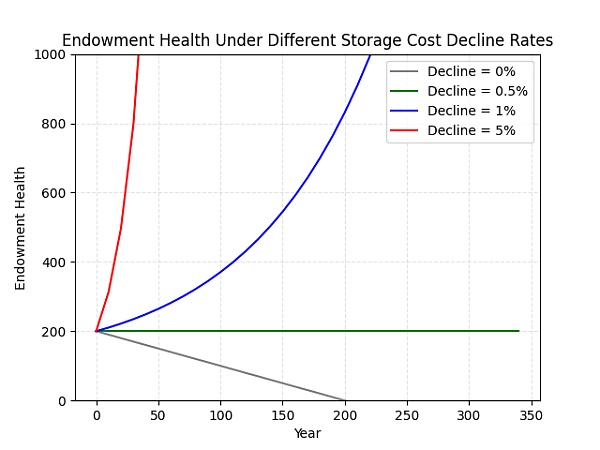
图 1:基金的健康状况受到协议化 kryder+ 速率(0.5%)与实际 kryder+ 速率之间的差异以及代币价格变化的影响。
用户支付当前价格下复制存储 200 年的费用,这样只需 0.5% 的 kryder+ 速率就足以在没有代币价格变化的情况下无限期地维持基金。然而在过去的 50 年里,存储成本的实际下降速率一直维持在平均每年约 38.5% 的状态。鉴于存在显著的激励动机和改进空间,这一趋势大概率会持续保持下去。此外,实际 Kyder+ 速率与协议化 0.5% 的 kryder+ 速率之间的差值可以被调整,来为代币价格波动提供宽阔的安全边际,这也会随时间推移而导致代币供应的通货紧缩。
去中心化内容政策
Arweave 网络采用了一个没有中心化控制与审核的去中心化分层内容政策系统。这个系统的基本原则是自愿性:每个参与者都可以自由选择他们想要存储和提供的数据,协议不设任何强制要求。这一系统允许网络中的每个参与者创建并运营自己的内容政策,无需其他人的共识。这一做法的结果是形成了内容政策的多样化选择,具体体现在三个不同层面:
矿工:由于矿工会对数据进行存储并公开他们的内容,这就会受到任何国家或地区法律和规定的约束。所以网络中的矿工可以对他们存储的数据运行任意计算(包括各种形式的文本、图像、视频等分析),以筛选出他们认为非法或不当的内容。这使他们避免存储不符合当地法规的非法内容。
网关:用户通常通过网关访问 Arweave 上的内容。网关充当门户,允许用户和开发者在不运行自己节点的情况下访问 Arweave 网络中的数据。就像矿工可以选择自己对存储数据的内容政策一样,网关也能独立决定它们索引和提供哪些内容。此外,网络中网关的互操作性允许用户选择符合个人信仰和价值观的网关。
应用程序:可能影响 Arweave 用户的最后一层内容审核是在应用程序层面。基于 Arweave 数据构建的每个应用程序可能会在其接口提供的内容上使用额外的过滤器,这取决于开发者的代码实现。这些应用程序层面的内容政策可以嵌入到应用程序本身的源代码中,并不可变地存储在 Arweave 上 — 这使用户能够永久信赖应用程序将如何进行内容审核。
实时更新
- 6月 25, 2024 4:59 下午Bitcoin spot ETFs could hit longest outflow streak since debutUS spot Bitcoin exchange-traded funds (ETFs) are on track to notch their longest-selling stretch after recording an outflow of $174 million on Monday, the seventh in a row, according to data from SoSoValue.On Monday, Grayscales GBTC recorded $90 million in withdrawals, while Fidelitys FBTC experienced $35 million in outflows.Franklin Templeton's EZBC saw its first net outflow since May 2, with... source: https://cryptobriefing.com/bitcoin-etf-outflow-streak/
- 6月 25, 2024 4:56 下午1 Trillion Shiba Inu (SHIB) Transfer Stuns World's Largest ExchangeIs it over for SHIB? Epic one trillion Shiba Inu transfer hits Binance amid chaos on crypto market source: https://u.today/1-trillion-shiba-inu-shib-transfer-stuns-worlds-largest-exchange
- 6月 25, 2024 4:53 下午三地址从交易所累计转出价值1374万美金的PEPE据链上分析师@ai_9684xtpa 监测,三个地址累计从交易所转出价值 1347 万美金的 PEPE。 其中地址 0x06b 和地址 0x855 操作系首次建仓 PEPE,地址 0x837 疑似计划卖出 7000 亿枚代币,后又转回 6000 亿枚 PEPE。据 Scopechat 数据显示,过去 24 小时 PEPE 链上净买入金额已达到 202 万美金,是上周买入均值的 2.88 倍。
- 6月 25, 2024 4:51 下午Coinbase’s Crypto Asset Accounting Practices Could Lead the Firm in Trouble, Here’s Why?Is Coinbase using its method to adjust crypto impairment costs in its financial reports? The cryptocurrency exchange is facing scrutiny for how it accounts for crypto assets. Recently, Coinbase changed its accounting practices ahead of schedule, shifting how it reports the value of these assets. This pre-scheduled strategy has put Coinbase in trouble, let’s see … source: https://coinpedia.org/news/coinbases-crypto-asset-accounting-practices-could-lead-the-firm-in-trouble-heres-why/
- 6月 25, 2024 4:47 下午التحليل الفنى للنفط الخام بعد مكاسبه الاعلى منذ شهرينأستقرت العقود الآجلة لخام غرب تكساس الوسيط عند مستوى أقل بقليل من 82 دولارًا للبرميل اليوم الثلاثاء، لتحوم عند أعلى مستوياتها منذ ما يقرب من شهرين مع استمرار المخاطر الجيوسياسية في أوروبا الشرقية والشرق الأوسط في دعم أسعار النفط الخام. ومن جانبها فقد قالت أوكرانيا يوم الاثنين بإنها ضربت مؤخرًا أكثر من 30 منشأة روسية … source: https://www.tradersup.com/%d8%a3%d8%ae%d8%a8%d8%a7%d8%b1-%d8%a7%d9%84%d8%b3%d9%84%d8%b9/%d8%a3%d8%ae%d8%a8%d8%a7%d8%b1-%d8%a3%d8%b3%d8%b9%d8%a7%d8%b1-%d8%a7%d9%84%d9%86%d9%81%d8%b7-%d8%a7%d9%84%d9%8a%d9%88%d9%85/%d8%a7%d9%84%d8%aa%d8%ad%d9%84%d9%8a%d9%84-%d8%a7%d9%84%d9%81%d9%86%d9%89-%d9%84%d9%84%d9%86%d9%81%d8%b7-%d8%a7%d9%84%d8%ae%d8%a7%d9%85-%d8%a8%d8%b9%d8%af-%d9%85%d9%83%d8%a7%d8%b3%d8%a8%d9%87-%d8%a7/131823
- 6月 25, 2024 4:46 下午Passive Investing Craze Elevates AUM of ETFsExplore how the surge in passive investing is propelling the AUM of ETFs to new heights The passive investing revolution is sweeping the financial world, significantly elevating the assets under management (AUM) of exchange-traded funds (ETFs). With a growing number of investors favoring the cost-efficiency, simplicity, and broad market exposure that passive investing offers, ETFs [...] source: https://sfctoday.com/passive-investing-craze-elevates-aum-of-etfs/
- 6月 25, 2024 4:45 下午위믹스 7/1 브리오슈 하드포크...4.35억 WEMIX 소각 등위믹스(WEMIX)는 7월 1일 0시 8분 브리오슈 하드포크를 적용한다고 공지했다. 1) 반감기 도입으로 인한 민팅 수량 변경, 2) 재단 보유 리저브 물량 중 약 4.35억개 소각, 3) 유통 계획에 따른 생태계 발전 기금 / 위믹스 보유 미유통량 / 개발비 분배 등이 주요 골자다. 위믹스 최대 공급량은 5.88억개로 확정되어 현재 기준 9억 8천만개에서 60%로 축소된다. 공지일 기준 브리오슈 하드포크 예상 소각 수량은 4.35억개다.
- 6月 25, 2024 4:44 下午Promontory Technologies宣布推出其Promontory Alpha基金,CEO为麒麟投资联创Promontory Technologies 宣布推出其 Promontory Alpha 基金。据了解,这是一种量化、系统化、多策略的方法,用于交易流动性强的上市数字(加密)资产。该基金旨在保持市场中性并避免大幅下跌,为非美国投资者提供英属维尔京群岛投资工具,为美国投资者提供特拉华州 LP。 Promontory 首席执行官 Jackson Fu 是上海量化对冲基金管理公司麒麟投资的联合创始人,自 2016 年成立以来,麒麟管理的资产管理规模达 50-70 亿美元,风险调整后表现优异。(Decrypt)
- 6月 25, 2024 4:36 下午The Death of Iran’s President: What It Means for Cryptocurrency and Sanctions EvasionThe unexpected death of Iranian President Ebrahim Raisi has sent shockwaves through the geopolitical landscape, raising questions about the future of Iran’s political stability and economic policies. source: https://cryptonews.com/news/the-death-of-irans-president-what-it-means-for-cryptocurrency-and-sanctions-evasion.htm
- 6月 25, 2024 4:00 下午BTC続落で一時6万ドル割れ Mt.Goxが10年越しの弁済開始時期を発表【仮想通貨相場】24日のビットコイン(BTC)対円相場は下値を模索する展開となり、終値は5月14日ぶりに1000万円を割り込んだ。 source: https://jp.cointelegraph.com/news/dmm-bitcoin-market-report-2024-0625














