谷歌反击:Project Astra硬刚GPT-4o Veo对抗Sora


来源:机器之心
机器之心编辑部
通用的 AI,能够真正日常用的 AI,不做成这样现在都不好意思开发布会了。
5 月 15 日凌晨,一年一度的「科技界春晚」Google I/O 开发者大会正式开幕。长达 110 分钟的主 Keynote 提到了几次人工智能?谷歌自己统计了一下:

是的,每一分钟都在讲 AI。
生成式 AI 的竞争,最近又达到了新的高潮,本次 I/O 大会的内容自然全面围绕人工智能展开。
「一年前在这个舞台上,我们首次分享了原生多模态大模型 Gemini 的计划。它标志着新一代的 I/O,」谷歌首席执行官桑达尔・皮查伊(Sundar Pichai)说道。「今天,我们希望每个人都能从 Gemini 的技术中受益。这些突破性的功能将进入搜索、图片、生产力工具、安卓系统等方方面面。」
24 小时以前,OpenAI 故意抢先发布 GPT-4o,通过实时的语音、视频和文本交互震撼了全世界。今天,谷歌展示的 Project Astra 和 Veo,直接对标了目前 OpenAI 领先的 GPT-4o 与 Sora。
这是 Project Astra 原型的实时拍摄:
我们正在见证最高端的商战,以最朴实的方式进行着。
最新版 Gemini 革新谷歌生态
在 I/O 大会上,谷歌展示了最新版 Gemini 加持的搜索能力。
25 年前,谷歌通过搜索引擎推动了第一波信息时代的浪潮。现在,随着生成式 AI 技术的演进,搜索引擎可以更好地帮你回答问题,它可以更好地利用上下文内容、位置感知和实时信息能力。
基于最新版本的定制化 Gemini 大模型,你可以对搜索引擎提出任何你想到的事情,或任何需要完成的事 —— 从研究到计划到想象,谷歌将负责所有工作。
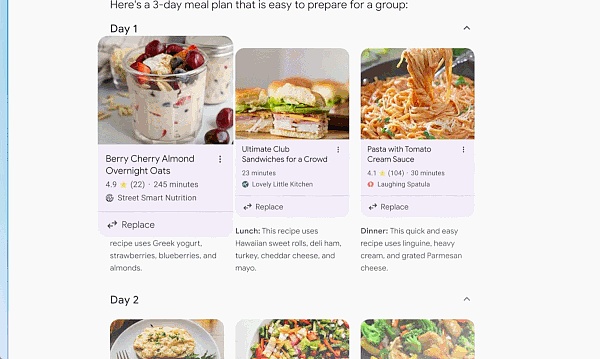
有时你想要快速得到答案,但没有时间将所有信息拼凑在一起。这个时候,搜索引擎将通过 AI 概述为你完成工作。通过人工智能概述,AI 可以自动访问大量网站来提供一个复杂问题的答案。
借助定制 Gemini 的多步推理功能,AI 概述将有助于解决日益复杂的问题。你无需再将问题分解为多个搜索,现在可以一次性提出最复杂的问题,以及你想到的所有细微差别和注意事项。
除了为复杂问题找到正确的答案或信息之外,搜索引擎还可以与你一起,一步步制定计划。
在 I/O 大会上,谷歌重点强调了大模型的多模态和长文本能力。技术的进步为 Google Workspace 等生产力工具变得更加智能化。
例如,现在我们可以要求 Gemini 总结一下学校最近发来的所有电子邮件。它会在后台识别相关的 Email,甚至分析 PDF 等附件。随后你就能获得其中的要点和行动项目的摘要。

如果你正在旅行,无法参加项目会议,而会议的录音长达一个小时。如果是 Google Meet 上开的会,你可以要求 Gemini 给你介绍一下重点。有一个小组在寻找志愿者,那天你有空。Gemini 可以帮你写一封邮件进行申请。
更进一步,谷歌在大模型 Agent 上看到了更多的机会,认为它们可作为具有推理、计划和记忆能力的智能系统。利用 Agent 的应用能够提前「思考」多个步骤,并跨软件和系统工作,更加便捷地帮你完成任务。这种思路已经在搜索引擎等产品中得到了体现,人们都可以直接看到 AI 能力的提升。
至少在全家桶应用方面,谷歌是领先于 OpenAI 的。
Gemini 家族大更新
Project Astra 上线
生态上谷歌有先天优势,但大模型基础很重要,谷歌为此整合了自身团队和 DeepMind 的力量。今天哈萨比斯也首次在 I/O 大会上登台,亲自介绍了神秘的新模型。

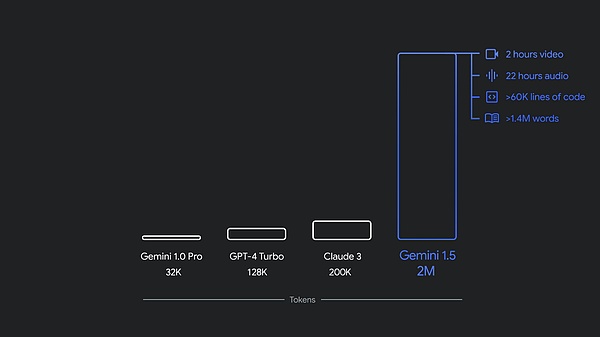
去年 12 月,谷歌推出了首款原生多模态模型 Gemini 1.0,共有三种尺寸:Ultra、Pro 和 Nano。仅仅几个月后,谷歌发布新版本 1.5 Pro,其性能得到了增强,并且上下文窗口突破了 100 万 token。
现在,谷歌宣布在 Gemini 系列模型中引入了一系列更新,包括新的 Gemini 1.5 Flash(这是谷歌追求速度和效率的轻量级模型)以及 Project Astra(这是谷歌对人工智能助手未来的愿景)。
目前,1.5 Pro 和 1.5 Flash 均已提供公共预览版,并在 Google AI Studio 和 Vertex AI 中提供 100 万 token 上下文窗口。现在,1.5 Pro 还通过候补名单向使用 API 的开发人员和 Google Cloud 客户提供了 200 万 token 上下文窗口。
此外,Gemini Nano 也从纯文本输入扩展到可以图片输入。今年晚些时候,从 Pixel 开始,谷歌将推出多模态 Gemini Nano 。这意味着手机用户不仅能够处理文本输入,还能够理解更多上下文信息,例如视觉、声音和口语。
Gemini 家族迎来新成员:Gemini 1.5 Flash
新的 1.5 Flash 针对速度和效率进行了优化。
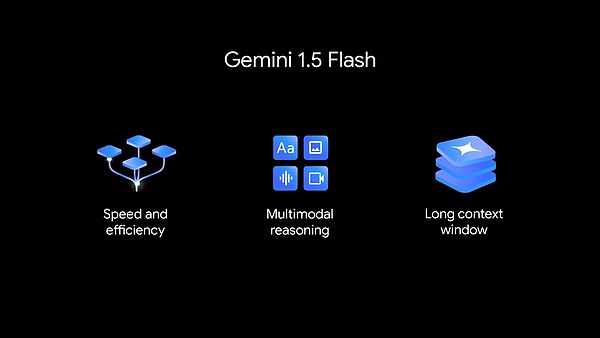
1.5 Flash 是 Gemini 模型系列的最新成员,也是 API 中速度最快的 Gemini 模型。它针对大规模、大批量、高频任务进行了优化,服务更具成本效益,并具有突破性的长上下文窗口(100 万 token )。

Gemini 1.5 Flash 具有很强的多模态推理能力,并具有突破性的长上下文窗口。
1.5 Flash 擅长摘要、聊天应用程序、图像和视频字幕、从长文档和表格中提取数据等。这是因为 1.5 Pro 通过一个名为「蒸馏」的过程对其进行了训练,将较大模型中最基本的知识和技能迁移到较小、更高效的模型中。
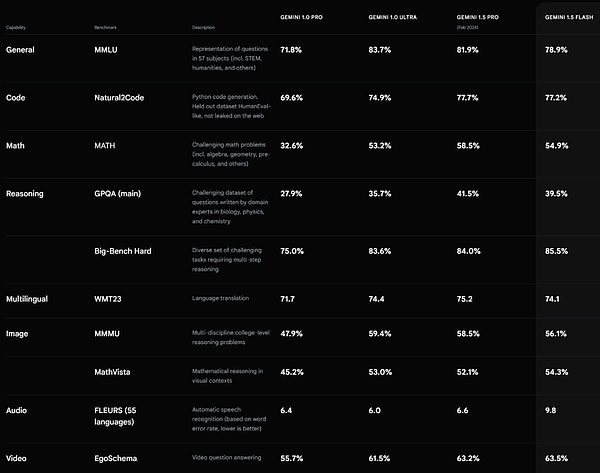
Gemini 1.5 Flash 性能表现。来源 https://deepmind.google/technologies/gemini/#introduction
改进的 Gemini 1.5 Pro 上下文窗口扩展到 200 万 token
谷歌提到,如今有超过 150 万的开发人员在使用 Gemini 模型,超过 20 亿的产品用户都用到了 Gemini。

在过去的几个月里,谷歌除了将 Gemini 1.5 Pro 上下文窗口扩展到 200 万 token 之外,谷歌还通过数据和算法的改进增强了其代码生成、逻辑推理和规划、多轮对话以及音频和图像理解能力。

1.5 Pro 现在可以遵循日益复杂和细致的指令,包括那些指定涉及角色,格式和风格的产品级行为的指令。此外,谷歌还让用户能够通过设置系统指令来引导模型行为。
现在,谷歌在 Gemini API 和 Google AI Studio 中添加了音频理解,因此 1.5 Pro 现在可以对 Google AI Studio 中上传的视频图像和音频进行推理。此外,谷歌还将 1.5 Pro 集成到 Google 产品中,包括 Gemini Advanced 和 Workspace 应用程序。
Gemini 1.5 Pro 的定价为每 100 万 token 3.5 美元。
其实,Gemini 最令人兴奋的转变之一是 Google 搜索。
在过去的一年里,作为搜索生成体验的一部分,Google 搜索回答了数十亿个查询。现在,人们可以使用它以全新的方式进行搜索,提出新类型的问题、更长、更复杂的查询,甚至使用照片进行搜索,并获得网络所提供的最佳信息。

谷歌即将推出 Ask Photos 功能。以 Google Photos 举例,该功能大约在九年前推出。如今,用户每天上传的照片和视频数量超过 60 亿张。人们喜欢使用照片来搜索他们的生活。Gemini 让这一切变得更加容易。
假设你正在停车场付款,但不记得自己的车牌号码。之前,你可以在照片中搜索关键字,然后滚动浏览多年的照片,寻找车牌。现在,你只需询问照片即可。

又比如,你回忆女儿露西娅的早期生活。现在,你可以问照片:露西亚什么时候学会游泳的?你还可以跟进一些更复杂的事情:告诉我露西娅的游泳进展如何。
在这里,Gemini 超越了简单的搜索,识别了不同的背景 —— 包括游泳池、大海等不同场景,照片将所有内容汇总在一起,以便用户查看。谷歌将于今年夏天推出 Ask Photos 功能,并且还将推出更多功能。


新一代开源大模型 Gemma 2
今天,谷歌还发布了开源大模型 Gemma 的一系列更新 ——Gemma 2 来了。
据介绍,Gemma 2 采用全新架构,旨在实现突破性的性能和效率,新开源的模型参数为 27B。

此外,Gemma 家族也在随着 PaliGemma 的扩展而扩展,PaliGemma 是谷歌受 PaLI-3 启发的第一个视觉语言模型。
通用 AI 智能体 Project Astra
一直以来,智能体都是 Google DeepMind 的重点研究方向。
昨天,我们围观了 OpenAI 的 GPT-4o,为其强大的实时语音、视频交互能力所震撼。
今天,DeepMind 的视觉与语音交互通用 AI 智能体项目 Project Astra 亮相,这是 Google DeepMind 对未来 AI 助手的一个展望。
谷歌表示,为了真正发挥作用,智能体需要像人类一样理解和响应复杂、动态的真实世界,也需要吸收并记住所看到和听到的内容,以了解上下文并采取行动。此外,智能体还需要具有主动性、可教育和个性化,以便用户可以自然地与它交谈,没有滞后或延迟。
在过去的几年里,谷歌一直致力于改进模型的感知、推理和对话方式,以使交互的速度和质量更加自然。
在今天的 Keynote 中, Google DeepMind 展示了 Project Astra 的交互能力:
据介绍,谷歌是在 Gemini 的基础上开发了智能体原型,它可以通过连续编码视频帧、将视频和语音输入组合到事件时间线中并缓存此信息以进行有效调用,从而更快地处理信息。
通过语音模型,谷歌还强化了智能体的发音,为智能体提供了更广泛的语调。这些智能体可以更好地理解他们所使用的上下文,并在对话中快速做出响应。
这里简单评论一下。机器之心感觉 Project Astra 项目发布的 Demo,在交互体验上要比 GPT-4o 实时演示的能力要差许多。无论是响应的时长、语音的情感丰富度、可打断等方面,GPT-4o 的交互体验似乎更自然。不知道读者们感觉如何?
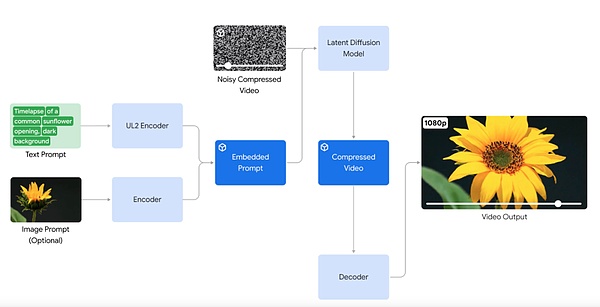
反击 Sora:发布视频生成模型 Veo
在 AI 生成视频方面,谷歌宣布推出视频生成模型 Veo。Veo 能够生成各种风格的高质量 1080p 分辨率视频,时长可以超过一分钟。
凭借对自然语言和视觉语义的深入理解,Veo 模型在理解视频内容、渲染高清图像、模拟物理原理等方面都有所突破。Veo 生成的视频能够准确、细致地表达用户的创作意图。
例如,输入文本 prompt:
Many spotted jellyfish pulsating under water. Their bodies are transparent and glowing in deep ocean.
(许多斑点水母在水下搏动。它们的身体透明,在深海中闪闪发光。)
再比如生成人物视频,输入 prompt:
A lone cowboy rides his horse across an open plain at beautiful sunset, soft light, warm colors.
(在美丽的日落、柔和的光线、温暖的色彩下,一个孤独的牛仔骑着马穿过开阔的平原。)
近景人物视频,输入 prompt:
A woman sitting alone in a dimly lit cafe, a half-finished novel open in front of her. Film noir aesthetic, mysterious atmosphere. Black and white.
(一个女人独自坐在灯光昏暗的咖啡馆里,一本未完成的小说摊在她面前。黑色电影唯美,神秘气氛。黑白。)
值得注意的是,Veo 模型提供了前所未有的创意控制水平,并理解「延时拍摄」、「航拍」等电影术语,使视频连贯、逼真。
例如电影级海岸线航拍镜头,输入 prompt:
Drone shot along the Hawaii jungle coastline, sunny day
(无人机沿夏威夷丛林海岸线拍摄,阳光明媚的日子)
Veo 还支持以图像和文本一起作为 prompt,来生成视频。通过提供参考图像与文本提示,Veo 生成的视频会遵循图像风格和用户文本说明。
有趣的是,谷歌发布的 demo 是 Veo 生成的「羊驼」视频,很容易让人联想到 Meta 的开源系列模型 Llama。

在长视频方面,Veo 能够制作 60 秒甚至更长的视频。它可以通过单个 prompt 来完成此操作,也可以通过提供一系列 prompt 来完成此操作,这些 prompt 一起讲述一个故事。这一点对视频生成模型应用于影视制作非常关键。
Veo 以谷歌的视觉内容生成工作为基础,包括生成式查询网络 (GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere 等。
从今天开始,谷歌会为一些创作者在 VideoFX 中提供预览版 Veo,创作者可以加入谷歌的 waitlist。谷歌还将把 Veo 的一些功能引入 YouTube Shorts 等产品。
文生图新模型 Imagen 3
在文本到图像生成方面,谷歌再次升级了系列模型 —— 发布 Imagen 3。
Imagen 3 在生成细节、光照、干扰等方面进行了优化升级,并且理解 prompt 的能力显著增强。
为了帮助 Imagen 3 从较长的 prompt 中捕捉细节,例如特定的摄像机角度或构图,谷歌在训练数据中每个图像的标题中添加了更丰富的细节。
例如,在输入 prompt 中添加「在前景中略微虚焦」、「温暖光线」等,Imagen 3 就可以按照要求生成图像:

此外,谷歌特别针对图像生成中「文字模糊」的问题进行了改进,即优化了图像渲染,使生成图像中文字清晰并风格化。

为了提高可用性,Imagen 3 将提供多个版本,每个版本都针对不同类型的任务进行了优化。
从今天开始,谷歌为一些创作者在 ImageFX 中提供 Imagen 3 预览版,用户可以注册加入 waitlist。
第六代 TPU 芯片 Trillium
生成式 AI 正在改变人类与技术交互的方式,同时为企业带来巨大的增效机会。但这些进步需要更多的计算、内存和通信能力,以训练和微调功能最强大的模型。
为此,谷歌推出第六代 TPU Trillium,这是迄今为止性能最强大、能效最高的 TPU,将于 2024 年底正式上市。
TPU Trillium 是一种高度定制化的 AI 专用硬件,此次 Google I/O 大会上宣布的多项创新,包括 Gemini 1.5 Flash、Imagen 3 和 Gemma 2 等新模型,均在 TPU 上进行训练并使用 TPU 提供服务。

据介绍,与 TPU v5e 相比,Trillium TPU 的每芯片峰值计算性能提高了 4.7 倍,同时它还把高带宽内存(HBM)以及芯片间互连(ICI)带宽加倍。此外,Trillium 配备了第三代 SparseCore,专门用于处理高级排名和推荐工作负载中常见的超大型嵌入。
谷歌表示,Trillium 能够以更快的速度训练新一代 AI 模型,同时减少延迟和降低成本。此外,Trillium 还被称为迄今为止谷歌最具可持续性的 TPU,与其前代产品相比,能效提高了超过 67%。
Trillium 可以在单个高带宽、低延迟的计算集群(pod)中扩展到多达 256 个 TPU(张量处理单元)。除了这种集群级别的扩展能力之外,通过多片技术(multislice technology)和智能处理单元(Titanium Intelligence Processing Units,IPUs),Trillium TPU 可以扩展到数百个集群,连接成千上万的芯片,形成一个由每秒数 PB(multi-petabit-per-second)数据中心网络互联的超级计算机。
谷歌早在 2013 年就推出了首款 TPU v1,随后在 2017 年推出了云 TPU,这些 TPU 一直在为实时语音搜索、照片对象识别、语言翻译等各种服务提供支持,甚至为自动驾驶汽车公司 Nuro 等产品提供技术动力。
Trillium 也是谷歌 AI Hypercomputer 的一部分,这是一种开创性的超级计算架构,专为处理尖端的 AI 工作负载而设计。谷歌正在与 Hugging Face 合作,优化开源模型训练和服务的硬件。

以上,就是今天谷歌 I/O 大会的所有重点内容了。可以看出,谷歌在大模型技术与产品方面与 OpenAI 展开了全面竞争的态势。而通过这两天 OpenAI 与谷歌的发布,我们也能发现大模型竞争进入了到了一个新的阶段:多模态、更自然地交互体验成为了大模型技术产品化并为更多人所接受的关键。
期待 2024 年,大模型技术与产品创新,能为我们带来更多的惊喜。
更多新闻 구글소라
- 5月 21, 2024 6:18 晚上Aizel Network 获谷歌云批准,加入谷歌初创企业云计划据 Odaily 报道,人工智能推理网络 Aizel Network 宣布已获得谷歌云(Google Cloud)的批准,并随后被纳入谷歌初创企业云计划(Google for Startups Cloud)。这项批准为 Aizel Network 提供了价值高达 35 万美元的谷歌云支持,以及额外的技术和业务资源。 通过加入该计划和利用谷歌云的支持,Aizel Network 旨在加速其在人工智能和 Web3 领域的发展。此举标志着 Aizel Network 在继续扩大其在技术领域的影响力方面迈出了重要一步。谷歌初创企业云计划(Google for Startups Cloud)以为初创企业提供成长和成功所需的资源而著称,Aizel Network 被纳入该计划,证明了其在人工智能和 Web3 领域的潜力和贡献价值。
- 4月 30, 2024 8:13 晚上Sui宣布与Google Cloud达成合作Layer 1 区块链和智能合约平台 Sui 宣布与 Google Cloud 合作,以推动 Web3 创新。 Sui 表示,由 Facebook 的 Libra 和 Diem 项目核心研究团队领导,将与 Google 合作解决 Web3 领域的关键挑战,包括安全性、可扩展性、开发者工具和用户体验。Google Cloud 已将 Sui 区块链数据整合到 BigQuery 公共数据集中,为开发者提供强大的分析工具,以解锁新的见解和创新的去中心化应用程序。(Venturebeat)
- 4月 30, 2024 8:03 晚上수이, 구글 클라우드와 파트너십데일리안에 따르면 레이어1 블록체인 프로젝트 수이(SUI)가 구글 클라우드와 파트너십을 체결했다고 밝혔다. 양사는 이번 파트너십을 통해 사용자 경험 강화, 확장성 개선에 초점을 둔 툴을 개발자들에게 제공할 계획이다.
- 4月 25, 2024 11:07 上午구글 클라우드, 웹3 포털 출시구글 클라우드가 공식 X를 통해 "웹3 전용 구글 클라우드인 '웹3 포털'을 출시했다"고 밝혔다. 웹 3포털은 △정보찾기 △퍼싯(Faucet) △교육(Learn) △스타트업 프로그램 탭으로 구성돼 있다. 이를 통해 사용자는 블록체인 기술에 대한 데이터 및 자료를 찾아볼 수 있으며 구글 클라우드 파트너의 개발 도구를 체험할 수 있다. 또 웹3에 대한 기본적인 지식을 습득할 수 있다. 퍼싯 탭을 통해서는 다양한 테스트넷에 배치된 암호화폐 컨트랙트를 배포하거나 트랜잭션을 디버깅 하는 등의 테스트넷 참여 서비스가 제공된다.
- 1月 19, 2024 12:03 凌晨엘프, 구글클라우드와 파트너십 체결탈중앙화 클라우드 컴퓨팅 블록체인 네트워크 엘프(ELF)가 공식 X(구 트위터) 계정을 통해 구글클라우드와 파트너십을 체결했다고 19일 밝혔다.
- 12月 29, 2023 6:05 晚上맵프로토콜, 구글 클라우드와 파트너십옴니체인 상호운용 인프라 겸 비트코인 레이어2 네트워크 맵프로토콜(MAPO,MAP)이 X를 통해 구글 클라우드와 파트너십을 체결했다고 밝혔다.
- 12月 10, 2023 11:56 晚上谷歌宣布修改加密货币政策搜索引擎巨头谷歌将对其接受的加密货币领域的广告进行政策调整。 继续阅读:谷歌宣布改变其加密货币政策 来源:https://en.bitcoinsistemi.com/google-announces-a-change-in-its-cryptocurrency-policy/
- 12月 06, 2023 8:07 晚上谷歌巴德预测索拉纳 2024 年的价格随着 ChatGPT 的推出,人们对人工智能(AI)的兴趣日益浓厚,同类平台也展示了它们的实用性。继续 来源: https://finbold.com/google-bard-predicts-solana-price-for-2024/
- 9月 01, 2023 7:47 晚上OP Labs聘请谷歌前高管担任首席运营官Odaily星球日报讯 OP Labs聘请谷歌前高管Prithvi Subburaj担任首席运营官。这一任命是在OP联创Karl Floersch转为OP Labs首席执行官之后下达的,Subburaj是领导层变动后的第一位高管。 Subburaj曾在谷歌担任软件工程方面的领导职务,他在谷歌最后管理业务为无线订阅服务Google Fi,于谷歌工作超15年。(The Block)


















