أصدر "الهجوم المضاد" من Google ما يقرب من 10 نماذج بين عشية وضحاها


المؤلف: Tu Min, CSDN
يشبه شهر مايو هذا الحلم بالعودة إلى مارس 2023، حيث تقام احتفالات الذكاء الاصطناعي المفعمة بالحيوية الواحدة تلو الأخرى.
ومع ذلك، سواء عن قصد أو عن غير قصد، في مارس من العام الماضي، عندما اختارت Google فتح نموذج اللغة الكبير PaLM API، أصدرت OpenAI أقوى نموذج GPT-4 في نفس الوقت تقريبًا وبعد بضعة أيام فقط، أعلنت شركة مايكروسوفت رسميًا في مؤتمر صحفي أن عائلة Office الخاصة بها قد أحدثت ثورة بواسطة GPT-4، مما جعل Google يبدو وكأنه يتجاهله الجميع.
من المحرج إلى حد ما، يبدو أن نفس الوضع يحدث هذا العام، فمن ناحية، جلبت OpenAI جهاز GPT4o الرائد الذي تمت ترقيته بالكامل في وقت مبكر من صباح أمس مع افتتاح حفل مهرجان الربيع للذكاء الاصطناعي لهذا الشهر ، ستعقد Microsoft Bulid 2024 الأسبوع المقبل، لذا، سواء تمكنت Google، التي تعرضت للهجوم مرة أخرى هذه المرة، من عكس وضع "مجموعتيها"، فسنحصل على لمحة عن ذلك من مؤتمر مطوري I/O 2024 الذي افتتح. باكرا هذا الصباح. .
إن مؤتمر I/O لهذا العام هو أيضًا العام الثامن الذي تنفذ فيه Google بوضوح استراتيجية "الذكاء الاصطناعي أولاً".
01 معاينة النقاط البارزة
كما هو متوقع، في هذه الكلمة الرئيسية التي تستغرق ساعتين تقريبًا، ""AI" هي كلمة رئيسية الذي يستمر طوال مؤتمر I/O، ولكن بشكل غير متوقع، تم ذكره ما يصل إلى 121 مرة. ليس من الصعب أن نرى قلق Google بشأن الذكاء الاصطناعي.

في مواجهة منافسين خارجيين شرسين، الرئيس التنفيذي لشركة Google ساندر بيتشاي (سوندار بيتشاي "لا يزال الذكاء الاصطناعي قال بيتشاي في مقابلة أجريت معه مؤخرًا في أحد البرامج: "إنها في المراحل الأولى من التطوير، وأعتقد أن جوجل ستنتصر في نهاية المطاف في هذه الحرب، تمامًا كما لم تكن جوجل أول شركة تقوم بالبحث".
في مؤتمر I/O، أكد ساندر بيتشاي أيضًا على هذه النقطة، "ما زلنا في المراحل الأولى من تحول منصات الذكاء الاصطناعي. بالنسبة للمبدعين والمطورين والشركات الناشئة والجميع، نرى فرصًا هائلة
قال Sundar Pichai إنه عندما تم إصدار Gemini العام الماضي، تم وضعه كنموذج كبير متعدد الوسائط يمكن أن يشمل النصوص والصور ومقاطع الفيديو والرموز وما إلى ذلك. في فبراير من هذا العام، أصدرت Google Gemini 1.5 Pro، وهو إنجاز كبير في مجال النصوص الطويلة، مما أدى إلى توسيع طول نافذة السياق إلى مليون رمز، أكثر من أي نموذج أساسي آخر واسع النطاق. واليوم، يستخدم أكثر من 1.5 مليون مطور نماذج Gemini في أدوات Google.
في المؤتمر الصحفي، شارك ساندر بيتشي أحدث التقدم داخل Google:
تطبيق Gemini متاح الآن على أنظمة Android و iOS. يتيح Gemini Advanced للمستخدمين إمكانية الوصول إلى أقوى نماذج Google.
ستطرح Google نسخة محسنة من Gemini 1.5 Pro لجميع المطورين في جميع أنحاء العالم. بالإضافة إلى ذلك، أصبح Gemini 1.5 Pro، الذي يحتوي على مليون سياق رمزي اليوم، متاحًا الآن للمستهلكين مباشرةً في Gemini Advanced، حيث يتوفر عبر 35 لغة.
قامت Google بتوسيع نافذة سياق Gemini 1.5 Pro إلى 2 مليون رمز مميز وجعلتها متاحة للمطورين كمعاينة خاصة.
على الرغم من أننا لا نزال في المراحل الأولى من Agent، فقد بدأت Google بالفعل في استكشاف وتجربة مشروع Astra، الذي يحلل العالم من خلال كاميرات الهواتف الذكية، ويحدد الرموز ويفسرها، يساعد البشر في العثور على النظارات، ويمكنه أيضًا تمييز الأصوات...
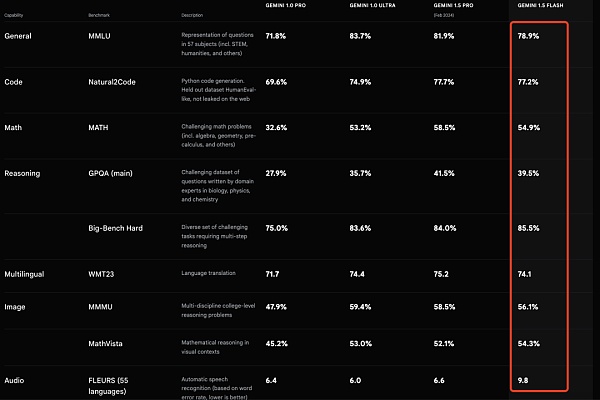
تم إصدار Gemini 1.5 Flash، وهو أخف وزنًا من Gemini 1.5 Pro، وهو يستهدف المهام المهمة. مثل الكمون المنخفض والتكلفة الأمثل.
تم إصدار Imagen 3، وهو نموذج Veo ونموذج الصور المولدة بالنص والذي يمكنه إنتاج مقاطع فيديو "عالية الجودة" بدقة 1080 بكسل.
يعتمد بنية جديدة، بحجم 27B، يتوفر Gemma 2.0؛
Android، أول نظام تشغيل محمول يتضمن نموذجًا أساسيًا مدمجًا للجهاز، ويدمج Gemini بعمق نموذج ويصبح قائمًا على الذكاء الاصطناعي من Google باعتباره نظام التشغيل الأساسي؛
تم إصدار الجيل السادس من مادة TPU Trillium مقارنة بالجيل السابق من مادة TPU v5e، أداء الحوسبة لكل شريحة بنسبة 4.7 مرات.
02 جوجل "مجنون"، وتم إصدار نماذج متعددة
إنه كذلك قال إن أولئك الذين يصنعون نماذج كبيرة "ضخمة" للغاية بشكل غير متوقع، في عملية التسريع للحاق بالركب، فإن "حجم" Google يفوق الخيال بكثير. وفي المؤتمر الصحفي، لم تقم Google بتحديث نماذجها الكبيرة السابقة فحسب، بل أصدرت أيضًا عددًا من النماذج الجديدة.
ترقية وتحديث Gemini 1.5 Pro
عندما تم إصدار Gemini العام الماضي، وضعته Google كنموذج كبير متعدد الوسائط يمكن أن يشمل النصوص والصور ومقاطع الفيديو والأكواد وما إلى ذلك للاستدلال. في فبراير من هذا العام، أصدرت Google Gemini 1.5 Pro، وهو إنجاز كبير في مجال النصوص الطويلة، مما أدى إلى توسيع طول نافذة السياق إلى مليون رمز، أكثر من أي نموذج أساسي آخر واسع النطاق.
في المؤتمر الصحفي، أجرت Google لأول مرة تحسينات في الجودة لبعض حالات الاستخدام الرئيسية لـ Gemini 1.5 Pro، مثل الترجمة والتشفير والاستدلال وما إلى ذلك، والتي يمكنها التعامل مع نطاق أوسع من المهام الأكثر تعقيدًا. يمكن للإصدار 1.5 Pro الآن اتباع التوجيهات المعقدة والدقيقة، بما في ذلك التوجيهات التي تحدد سلوك مستوى الإنتاج الذي يتضمن الأدوار والتنسيقات والأنماط. كما يسمح للمستخدمين بالتحكم في سلوك النموذج عن طريق ضبط أوامر النظام.
وفي الوقت نفسه، أضافت Google فهمًا صوتيًا إلى Gemini API وGoogle AI Studio، لذلك يمكن لـ 1.5 Pro الآن إجراء الاستدلال على الصور والصوت لمقاطع الفيديو التي تم تحميلها في Google AI Studio.
الأمر الجدير بالملاحظة هو أنه إذا كان سياق مليون رمز مميز طويل بما فيه الكفاية، فإن Google اليوم توسع قدراتها بشكل أكبر، وتوسع نافذة السياق إلى 2 مليون رمز مميز، ومع معاينة خاصة متاحة للمطورين في الإصدار 2، فهو يمثل الخطوة التالية نحو الهدف النهائي المتمثل في سياق غير محدود.
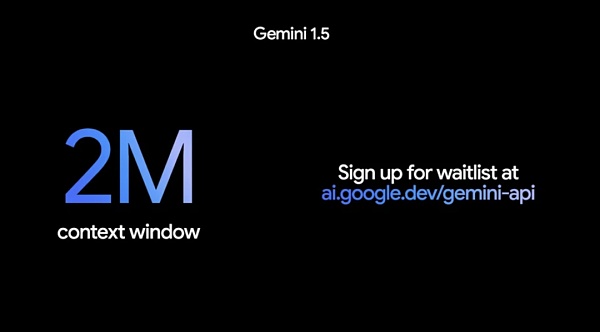
للوصول إلى 1.5 Pro مع نافذة سياق 2 مليون رمز مميز، تحتاج إلى الانضمام قائمة انتظار Google AI في Studio أو Vertex AI لعملاء Google Cloud.
نموذج جديد خفيف الوزن أكثر Gemini 1.5 Flash
Gemini 1.5 Flash، وهو نموذج خفيف الوزن مصمم لنموذج التوسعة، وهو أيضًا أسرع طراز Gemini في واجهة برمجة التطبيقات. لقد تم تحسينه للمهام التي يكون فيها زمن الاستجابة المنخفض والتكلفة أكثر أهمية، حيث يتم تقديم خدمة أكثر فعالية من حيث التكلفة مع نوافذ سياقية طويلة رائدة.

على الرغم من أنه أخف من طراز 1.5 Pro، إلا أنه يمكنه التعامل مع كميات كبيرة من المعلومات إجراء التفكير متعدد الوسائط. يحتوي Flash أيضًا على نافذة سياق مكونة من مليون رمز مميز بشكل افتراضي، مما يعني أنه يمكنك التعامل مع ساعة من الفيديو، أو 11 ساعة من الصوت، أو قاعدة تعليمات برمجية تتكون من أكثر من 30000 سطر من التعليمات البرمجية، أو أكثر من 700000 كلمة.
يتفوق برنامج Gemini 1.5 Flash في التلخيص والدردشة وترجمات الصور والفيديو واستخراج البيانات من المستندات والجداول الطويلة والمزيد. وذلك لأن 1.5 Pro يقوم بتدريبه من خلال عملية تسمى "التقطير"، حيث ينقل المعرفة والمهارات الأكثر أهمية من نموذج أكبر إلى نموذج أصغر وأكثر كفاءة.
تم تحديد سعر Gemini 1.5 Flash بـ 35 سنتًا لكل مليون رمز. وهذا أرخص قليلاً من سعر GPT-4o الذي يبلغ 5 دولارات لكل مليون رمز.
يتوفر كل من Gemini 1.5 Pro و1.5 Flash في المعاينة العامة ومتاحان في Google AI Studio وVertex AI.
يتوفر الآن أول نموذج مفتوح للغة المرئية من Google PaliGemma
PaliGemma هو VLM مفتوح قوي (نموذج لغة مرئية) مستوحى من PaLI-3. تم بناء PaliGemma على مكونات مفتوحة مثل نموذج رؤية SigLIP ونموذج لغة Gemma، وهو مصمم لتحقيق أداء ضبط متطور في مجموعة متنوعة من مهام اللغة المرئية. يتضمن ذلك التسميات التوضيحية للصور ومقاطع الفيديو القصيرة والإجابة المرئية على الأسئلة وفهم النص في الصور واكتشاف الكائنات وتجزئة الكائنات.
قالت Google إنه من أجل تعزيز الاستكشاف والبحث المفتوح، يتوفر PaliGemma من خلال مجموعة متنوعة من المنصات والموارد، ويمكنك العثور عليه على GitHub وHugging Face model وKaggle وVertex AI Model Garden وai. nvidia.com (باستخدام Find PaliGemma على TensorRT-LLM Acceleration) والتكامل بسهولة عبر JAX وHugging Face Transformers.
تم إصدار Gemma 2
ستتوفر جميع إصدارات Gemma 2 بأحجام جديدة وتتميز ببنية جديدة تمامًا مصممة لتحقيق أداء وكفاءة مذهلين. مع 27 مليار معلمة، تتمتع Gemma 2 بأداء مماثل لـ Llama 3 70B ولكنها نصف الحجم.

وفقًا لـ Google، فإن التصميم الفعال لـ Gemma 2 يقلل من مقدار الحوسبة المطلوبة أقل من نصف النماذج المماثلة. تم تحسين الطراز 27B للتشغيل على وحدات معالجة الرسومات من NVIDIA وبكفاءة على مضيف TPU واحد في Vertex AI، مما يجعله أسهل في النشر وأكثر فعالية من حيث التكلفة لمجموعة واسعة من المستخدمين.


سيتم إطلاق لعبة Gemma 2 في شهر يونيو.
Veo: نموذج إنشاء الفيديو الأحدث والأكثر تقدمًا
يمكن اعتباره معيارًا مقارنة بـ Sora من OpenAI، حيث أطلقت Google نموذج إنشاء الفيديو Veo اليوم. يمكنه إنشاء مقاطع فيديو عالية الجودة بدقة 1080 بكسل بمجموعة متنوعة من الأنماط السينمائية والمرئية، تدوم أكثر من دقيقة.
يعتمد Veo على سنوات عمل Google في نماذج الفيديو التوليدية، بما في ذلك Geneative Query Network (GQN) وDVD-GAN وImagen-Video وPhenaki وWALT وVideoPoet وLumiere. اجمع بين البنية وخوارزميات القياس والتقنيات الأخرى لتحسين الجودة ودقة المخرجات.
بدءًا من اليوم، يمكن للمستخدمين الانضمام إلى قائمة الانتظار للتقدم بطلب للحصول على Veo.
Imagen 3: نموذج تحويل النص إلى صورة عالي الجودة
يحتوي Imagen 3 الذي تم إصداره حديثًا على عناصر بصرية أقل تشتيتًا للانتباه من نموذج Google السابق ظلال أقل، يمكنه فهم اللغة الطبيعية بشكل أفضل، والقصد من وراء الإشارات، ودمج التفاصيل الصغيرة في الإشارات الأطول.

بدءًا من اليوم، يتوفر Imagen 3 لمبدعين محددين في المعاينة الخاصة والانضمام إلى ImageFX قائمة الانتظار. Imagen 3 قادم إلى Vertex AI.
الرؤية المستقبلية: مشروع وكيل الذكاء الاصطناعي العام Astra
يشير ما يسمى بالوكيل إلى الأنظمة الذكية التي تتمتع بقدرات التفكير والتخطيط والذاكرة يمكنه "التفكير" بخطوات متعددة للأمام والعمل عبر البرامج والأنظمة.
في المؤتمر الصحفي الذي عُقد اليوم، كشف الرئيس التنفيذي لشركة Google DeepMind والمؤسس المشارك Demis Harbis والوكلاء المستجيبون للكلام) إحدى المحاولات الرئيسية.
يعتمد هذا المشروع على Gemini، حيث قامت Google بتطوير وكيل نموذجي يمكنه إجراء مكالمات فعالة من خلال تشفير إطارات الفيديو بشكل مستمر، والجمع بين إدخال الفيديو والصوت في جدول زمني للأحداث، وتخزين هذه المعلومات مؤقتًا لإجراء مكالمات فعالة. معالجة المعلومات بشكل أسرع.
من خلال الاستفادة من نماذج الكلام، قامت Google أيضًا بتحسين نطقها، مما يمنح العملاء نطاقًا أوسع من النغمات. يمكن لهؤلاء الوكلاء فهم السياق الذي يعملون فيه بشكل أفضل والاستجابة بسرعة أثناء المحادثات.
في المثال الموضح في المؤتمر الصحفي، يستطيع Project Astra التعرف تلقائيًا على الأشياء التي تصدر أصواتًا في المشاهد الحقيقية، ويمكنه أيضًا تحديد موقع المكونات المحددة التي تصدر الأصوات بشكل مباشر، ويمكنه أيضًا تفسير الوظيفة من الكود الذي يظهر عليه يمكن أن يساعد البشر أيضًا في العثور على النظارات وما إلى ذلك.
"باستخدام تكنولوجيا كهذه، من السهل تخيل مستقبل حيث يمكن للأشخاص الحصول على مساعدين محترفين في مجال الذكاء الاصطناعي من خلال هواتفهم أو نظاراتهم. وستظهر بعض هذه الميزات في منتجات Google في وقت لاحق من هذا العام"، Google Express.
03ترقية Gemini Advanced، Gemini قابلة للتخصيص
الآن، يقدم Gemini 1.5 Pro المُحسّن اشتراك Gemini Advanced Under الاشتراك، وهو النسخة المحسنة من Gemini 1.5 Pro متاحة لجميع المطورين حول العالم، والتي يمكن استخدامها عبر 35 لغة.
كما ذكرنا سابقًا، يحتوي Gemini 1.5 Pro على مليون سياق رمزي افتراضيًا، مما يعني أن نافذة السياق الطويلة هذه تعني أن Gemini Advanced يمكنه فهم عدة مستندات كبيرة، يُقدر أن يصل إجماليها إلى 1500 صفحة، أو 100 صفحة. ملخص رسائل البريد الإلكتروني، والعمل على محتوى فيديو مدته ساعة أو قاعدة أكواد برمجية تضم أكثر من 30000 سطر.
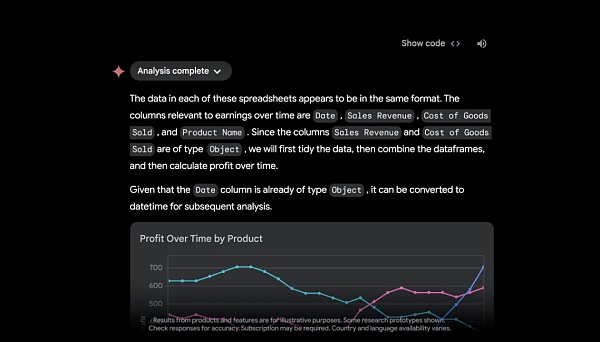
مع القدرة على تحميل الملفات إلى Google Drive أو مباشرة من جهازك، كشفت Google أنه قريبًا، سيعمل Gemini Advanced كمحلل بيانات، ويكتشف الرؤى من ملفات البيانات التي تم تحميلها (مثل جداول البيانات) ويبني ديناميكيًا تحديد المرئيات والرسوم البيانية تلقائيًا.
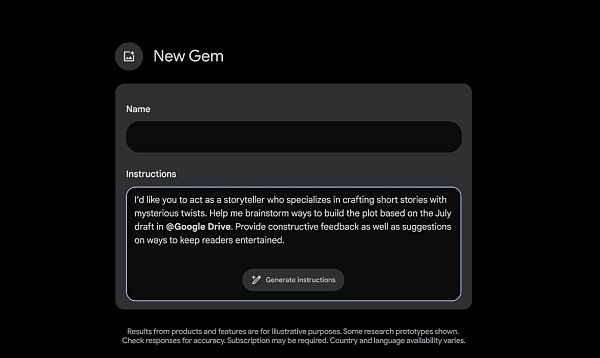
للحصول على تجربة أكثر تخصيصًا، سيتمكن مشتركو Gemini Advanced قريبًا من إنشاء الجواهر – إصدارات مخصصة من برج الجوزاء. يمكنك إنشاء أي جوهرة تريدها، مثل صديق التمرين، أو مساعد الطاهي، أو صديق البرمجة، أو دليل الكتابة الإبداعية. ما عليك سوى وصف ما تريد أن يفعله جوهرك وكيف تريد أن يستجيب، مثل "أنت مدرب الجري الخاص بي، أعطني خطة جري يومية، وكن إيجابيًا ومتفائلًا ومحفزًا، وسيقبل الجوزاء هذه التعليمات بمجرد." قم بتحسينها بنقرة واحدة لإنشاء جواهر تلبي احتياجاتك الخاصة.
04 استخدم الذكاء الاصطناعي لإعادة كتابة بحث Google< / h2>
بدون التطبيق العملي في سيناريوهات الأعمال، يبدو أن تكرار تكنولوجيا النماذج الكبيرة هو مجرد "حديث ورقي". وخلافًا للمسار الذي سلكته OpenAI، تتنافس كل من Google وMicrosoft على السرعة في مسار تطبيقات الذكاء الاصطناعي. بالنسبة لشركة جوجل، التي بدأت كشركة بحث، فمن المحتم ألا تفوتها موجة الذكاء الاصطناعي.
قالت ليز ريد، نائب الرئيس ورئيس قسم البحث في Google، "باستخدام الذكاء الاصطناعي التوليدي، يمكن للبحث أن يفعل أكثر مما تعتقد. لذا يمكنك التوصل إلى أي شيء تفكر فيه أو أي شيء تحتاج إليه إنجاز كل شيء - بدءًا من البحث وحتى التخطيط والعصف الذهني - ستتولى Google كل الإجراءات القانونية"
نظرات عامة على الذكاء الاصطناعي: "بحث واحد، كل المعلومات"< /. strong>
في المؤتمر الصحفي، أصدرت Google ميزة تسمى "نظرات عامة على الذكاء الاصطناعي" لتحقيق "بحث واحد، والحصول على جميع المعلومات".
لتبسيط الأمر، في بعض الأحيان تريد إجابة سريعة ولكن ليس لديك الوقت لتجميع كل المعلومات التي تحتاجها، مثل "أنت تبحث عن استوديو جديد لليوجا أو البيلاتس وترغب في ذلك" هل ترغب في استوديو يحظى بشعبية لدى السكان المحليين، ويمكن الوصول إليه بسهولة، ويقدم خصومات للأعضاء الجدد؟ "كل ما عليك فعله هو تحديد احتياجاتك وإجراء بحث، وستوفر لك AI Overviews إجابات على الأسئلة المعقدة.
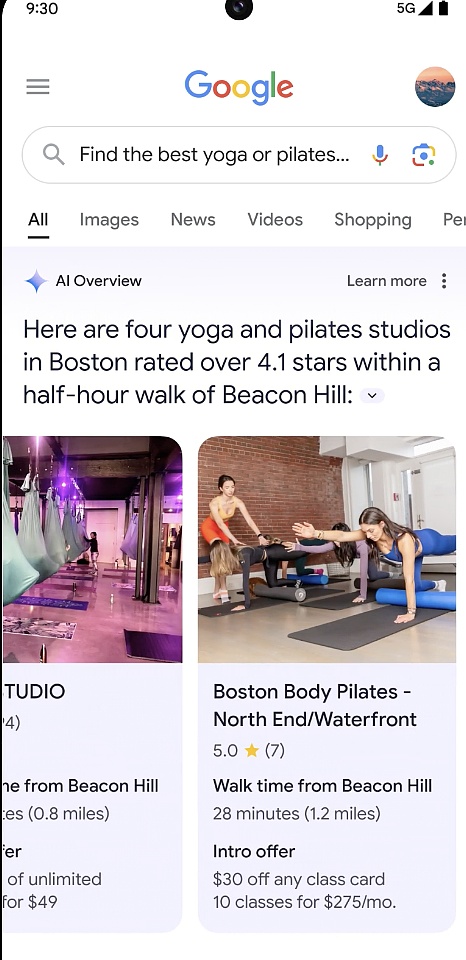
قم بتصوير مقاطع فيديو واحصل على مساعدة الذكاء الاصطناعي< br
قامت Google أيضًا بتحسين إمكانيات البحث المرئي نتيجة للتقدم في فهم الفيديو. يمكنك استخدام بحث الفيديو Google Lens لالتقاط صور للمشكلات التي تواجهها أو الأشياء التي تراها حولك (بما في ذلك الأجسام المتحركة)، حتى تتمكن من البحث عن الإجابات وتوفير الوقت والمتاعب الناجمة عن الأوصاف غير الواضحة في الكلمات.
ومع ذلك، يتم إطلاق الوظيفتين المذكورتين أعلاه حاليًا في الولايات المتحدة فقط، وسيتم إطلاقهما في المزيد من البلدان في المستقبل.
بالإضافة إلى مستوى البحث، فإن وصول النماذج الكبيرة سيؤدي أيضًا إلى تعزيز ذكاء المنتجات.
اسأل الصور
على مستوى تطبيق البحث عن الصور، قدمت Google وظيفة "اسأل الصور".
يمكنك استخدام برج الجوزاء للتعرف على المعلومات الخلفية المختلفة في الصور، مثل السؤال: متى تعلمت ابنتك السباحة؟ كيف تسير السباحة؟ تجمع الصور كل شيء معًا، مما يساعد المستخدمين على جمع المعلومات وحل الألغاز بسرعة.
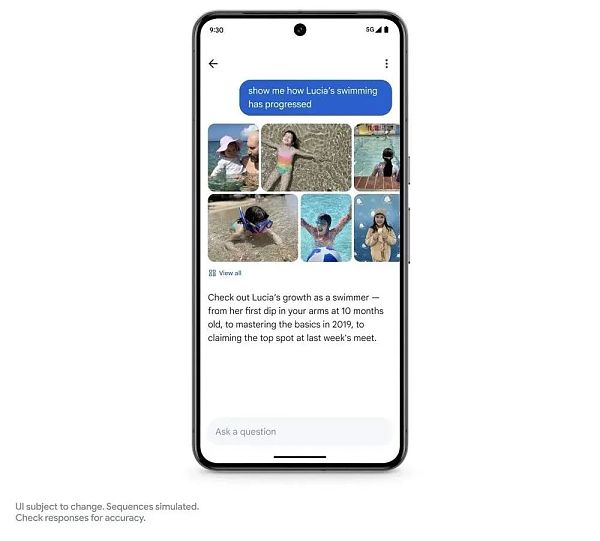
هذه الميزة ليست متاحة على الإنترنت بعد، وقالت Google إنه سيتم إطلاقها سيتم إطلاق هذا الصيف.
يأتي Gemini 1.5 Pro إلى Google Workspace
تدمج Google أيضًا نماذج كبيرة في Google Workspace، مثل البحث في البريد الإلكتروني في Gmail، والاحتفاظ على اطلاع بكل ما يحدث في مدرسة طفلك من خلال رسائل البريد الإلكتروني الأخيرة مع المدرسة. يمكننا أن نطلب من الجوزاء تلخيص جميع رسائل البريد الإلكتروني الأخيرة من المدرسة. فهو يحدد رسائل البريد الإلكتروني ذات الصلة في الخلفية ويحلل حتى المرفقات مثل ملفات PDF.
تمت إضافة إخراج الصوت في NotebookLM
NotebookLM هو تطبيق لتدوين الملاحظات يعمل بالذكاء الاصطناعي أطلقته Google في يوليو من العام الماضي، ويمكن تحميله في جميع أنحاء العالم ملخص إكمال المستندات للمستخدمين وأفكار الإنشاء.
استنادًا إلى تقنية النماذج الكبيرة متعددة الوسائط، أضافت Google وظيفة إخراج الصوت إلى هذا التطبيق. ويستخدم Gemini 1.5 Pro لأخذ المواد المصدرية للمستخدم وإنشاء محادثات صوتية تفاعلية مخصصة.
05 دمج نظام Android الخاص بـ Gemini بعمق
استخدم الذكاء الاصطناعي للتحكم في التشغيل تعد ترقية النظام أمرًا تروج له Microsoft وGoogle بقوة. باعتباره نظام تشغيل الأجهزة المحمولة رقم واحد في العالم، يتمتع Android بمليارات المستخدمين. قالت Google إنها قامت بدمج نموذج Gemini في Android وقدمت العديد من ميزات الذكاء الاصطناعي العملية.

على سبيل المثال، من خلال "الدائرة للبحث"، يمكن للمستخدمين بدلاً من التبديل بين التطبيقات ، استخدم تفاعلات بسيطة مثل رسم الدوائر والخربشات والنقر للحصول على مزيد من المعلومات. الآن، يمكن لـ Circle to Search مساعدة الطلاب على إكمال واجباتهم المنزلية، وعندما يضع الطلاب دائرة حول المطالبات التي يواجهونها، سيتم إعطاؤهم سلسلة من الحلول لحل المشكلة. شرح خطوة بخطوة لمسائل الفيزياء والرياضيات للحصول على فهم أعمق، وليس مجرد إجابات.
بالإضافة إلى ذلك، ستقوم Google قريبًا بتحديث تطبيق Gemini على نظام التشغيل Android، مما يسمح للمستخدمين بإظهار تراكب Gemini في الجزء العلوي من التطبيق، مما يسهل استخدام Gemini بطرق أكثر.
"Android هو أول نظام تشغيل للهواتف المحمولة يتضمن قاعدة أجهزة مدمجة Model"، مع Gemini Nano، يمكن لمستخدمي Android تجربة وظائف الذكاء الاصطناعي بسرعة. كشفت شركة جوجل أنها ستطلق أحدث طراز لها، وهو Gemini Nano، متعدد الوسائط، بدءًا من هاتف Pixel في وقت لاحق من هذا العام. وهذا يعني أن هواتف Pixel الجديدة يمكنها معالجة أكثر من مجرد إدخال النص، ولكنها يمكنها أيضًا فهم المزيد من المعلومات السياقية مثل البصر والصوت واللغة المنطوقة.
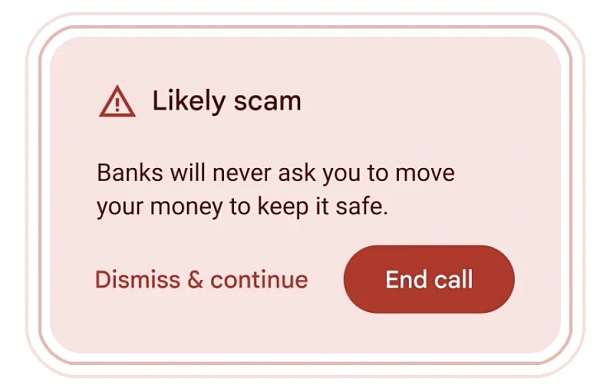
بالإضافة إلى ذلك، تستخدم Google برنامج Gemini Nano في Android لتوفير تنبيهات في الوقت الفعلي عندما تكتشف المحادثات أثناء المكالمات التي غالبًا ما ترتبط بعمليات احتيال، كما هو الحال عندما يسألك شخص يدعي أنه يعمل في مجال "الخدمات المصرفية" ستتلقى تنبيهًا بشكل عاجل عند قيامك بتحويل أموال، أو الدفع باستخدام بطاقة هدايا، أو طلب معلومات شخصية مثل رقم التعريف الشخصي للبطاقة أو كلمة المرور (هذه طلبات مصرفية غير شائعة)، ولكن هذه الميزة لا تزال قيد الاختبار.
06 الجيل السادس من مادة TPU ; Trillium
قال ساندر بيتشاي إن تدريب النماذج الحديثة يتطلب قدرًا كبيرًا من القوة الحاسوبية. على مدى السنوات الست الماضية، زاد الطلب الصناعي على حوسبة التعلم الآلي مليون مرة. ويزداد كل عام عشرة أضعاف.
من أجل التكيف مع الطلب المتزايد على حوسبة التعلم الآلي، أطلقت الجيل السادس من مادة TPU - Trillium مقارنة بالجيل السابق من مادة TPU v5e، وقد زاد أداء الحوسبة لكل شريحة Trillium بمقدار 4.7 مرة. ولتحقيق هذا المستوى من الأداء، قامت Google بزيادة حجم وحدة ضرب المصفوفة (MXU) وزيادة سرعة الساعة.
بالإضافة إلى ذلك، تم تجهيز Trillium بالجيل الثالث من SparseCore، وهو مسرع مصمم خصيصًا للتعامل مع عمليات التضمين الكبيرة جدًا الشائعة في أعباء عمل التصنيف والتوصيات المتقدمة. يمكن لـ Trillium TPU تدريب الموجة التالية من النماذج الأساسية بشكل أسرع وخدمتها بوقت استجابة أقل وتكلفة أقل.
يعتبر Trillium TPU أكثر كفاءة في استخدام الطاقة بنسبة تزيد عن 67% من TPU v5e.
يُذكر أن جوجل ستوفر Trillium لعملائها السحابيين بحلول نهاية عام 2024.
07التدابير الأمنية
بالإضافة إلى النموذج أعلاه وتحديثات المنتج، اتخذت Google أيضًا أحدث الإجراءات في الأمن، بهدف فيما يتعلق بإساءة استخدام الذكاء الاصطناعي وغيرها من المواقف.
من ناحية، أطلقت Google سلسلة نماذج جديدة تعتمد على Gemini وقامت بضبطها بدقة للتعلم، وإصدار LearnLM. فهو يدمج علوم التعلم المدعومة بالأبحاث والمبادئ الأكاديمية في منتجات Google للمساعدة في إدارة العبء المعرفي والتكيف مع أهداف المتعلمين واحتياجاتهم ودوافعهم.

ومن ناحية أخرى، ومن أجل تسهيل الحصول على المعرفة وهضمها، قامت Google ببناء أداة تجريبية جديدة، Illuminate، تستفيد من إمكانات السياق الطويل لـ Gemini 1.5 Pro لتحويل الأوراق البحثية المعقدة إلى محادثات صوتية قصيرة. يمكن لـ Illuminate إنشاء محادثة تتكون من صوتين تم إنشاؤهما بواسطة الذكاء الاصطناعي في دقائق، مما يوفر نظرة عامة ومناقشة مختصرة للأفكار الرئيسية من ورقة بحثية.
وأخيرًا، اعتمدت Google تقنية "الفريق الأحمر بمساعدة الذكاء الاصطناعي" لاختبار أنظمتها بشكل استباقي بحثًا عن نقاط الضعف ومحاولة كسرها، من خلال توسيع أداة العلامات المائية الخاصة بها SynthID إلى وضعين جديدين: النص والفيديو، مما يسهل التعرف على المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي.
08 ما رأيك في مؤتمر Google I/O؟
ما ورد أعلاه هو المحتوى الرئيسي لـ Google I/O 2024 Keynote. المنتجات غنية جدًا، لكن معظمها يحتاج إلى الانتظار.
ومع نهاية هذا المؤتمر الصحفي، أعرب العديد من الخبراء أيضًا عن بعض الآراء. من جيم فان، كبير مديري الأبحاث في NVIDIA:
Google I/O. بعض الأفكار: يبدو أن النموذج متعدد الوسائط للإدخال، ولكنه ليس متعدد الوسائط للإخراج. تظل نماذج Imagen-3 ونماذج الموسيقى منفصلة عن Gemini كمكونات منفصلة. يعد الدمج الأصلي لجميع المدخلات/المخرجات النموذجية اتجاهًا مستقبليًا لا مفر منه:
يتيح "استخدام صوت أكثر آلية"، مهام مثل مثل "التحدث بشكل أسرع مرتين" و"تحرير هذه الصورة بشكل متكرر" و"إنشاء شريط فكاهي متسق" ممكنة.
لا يتم فقدان المعلومات عبر حدود الوسائط، مثل المشاعر وأصوات الخلفية.
يوفر ميزات سياقية جديدة. يمكنك تعليم النموذج الخاص بك كيفية الجمع بين الحواس المختلفة بطرق جديدة مع عدد قليل من الأمثلة.
لم يتم تصنيع GPT-4o بشكل مثالي، ولكن عامل شكله صحيح. لاستخدام تشبيه Andrej's LLM-as-OS: نحتاج إلى أن يدعم النموذج أصلاً أكبر عدد ممكن من امتدادات الملفات.
تقوم شركة Google بشيء واحد صحيح: فهي تبذل أخيرًا جهودًا جادة لدمج الذكاء الاصطناعي في مربع البحث. أشعر بتدفق الوكيل: التخطيط، والتصفح المباشر، والإدخال متعدد الوسائط، كل ذلك من الصفحة المقصودة. أقوى خندق جوجل هو التوزيع. ليس من الضروري أن يكون برج الجوزاء هو النموذج الأفضل ليكون النموذج الأكثر استخدامًا في العالم.
قال عالم الذكاء الاصطناعي الشهير Andrew Ng، "تهانينا لجميع أصدقائي في Google على الإعلانات الرائعة في I/O، وأنا شخصيًا أتطلع إلى حصول Gemini على 200 10000 نافذة سياق إدخال رمزي ودعم أفضل للذكاء الاصطناعي على الجهاز - من شأنه أن يوفر فرصًا جديدة لمنشئي التطبيقات"

المزيد من الأخبار حول gemini 1.5 api access
- أبريل ١١، ٢٠٢٤ ٢:١٥ صChainlink Functions goes live on Base L2, enabling on-demand API accessChainlink Functions, a product of decentralized oracle network Chainlink, has officially launched on Base, the layer-2 blockchain incubated by Coinbase and secured through Ethereum's architecture.The integration provides smart contract developers on Base with access to trust-minimized compute infrastructure, enabling them to fetch data from APIs and perform custom computations from a... source: https://cryptobriefing.com/chainlink-functions-goeslive-base-l2/
- ديسمبر ١٥، ٢٠٢٣ ١:٣٠ صGoogle Offers Free Access to Gemini Pro for DevelopersGoogle has unveiled Gemini, a cutting-edge AI model lineup that includes Ultra, Pro, and Nano variants. Of particular interest to developers and enterprises is Gemini Pro, which promises advanced AI capabilities for applications. Gemini pro: Empowering developers with advanced AI Gemini Pro represents a significant leap forward in AI capabilities. It excels in processing text […] source: https://www.cryptopolitan.com/google-offers-free-access-to-gemini-pro/
- نوفمبر ١٩، ٢٠٢٣ ٩:٥٨ صشركة Kronos Research تعلق التداول بعد الوصول غير المصرح به إلى مفتاح واجهة برمجة التطبيقات (API).وفقًا لـ Foresight News، كشفت شركة Kronos Research المتخصصة في تحليل العملات المشفرة أنه منذ ما يقرب من ست ساعات، تم الوصول إلى بعض مفاتيح API الخاصة بها دون إذن. أثناء التحقيق، قامت شركة Kronos Research بتعليق جميع عمليات التداول مؤقتًا. والخسائر المحتملة ليست كبيرة بالنسبة لأصولها، وتعمل الشركة حالياً على استئناف التداول في أقرب وقت ممكن.
- نوفمبر ١٦، ٢٠٢٣ ٧:٤٨ صيعلن Elon Musk عن مرحلة الاختبار المبكر للوصول إلى واجهة برمجة التطبيقات الخاصة بمشروع xAI Project Grokوفقًا لـ Foresight News، أعلن Elon Musk مؤخرًا أن الوصول إلى Grok API لمشروع الذكاء الاصطناعي xAI أصبح الآن في مرحلة الاختبار المبكر. يقتصر الوصول حاليًا على عدد قليل من حسابات الشركاء. مع نضوج Grok، قد يتم توسيع نطاق الوصول ليشمل المزيد من المطورين.
- أكتوبر ٢٧، ٢٠٢٣ ٨:٢٤ ميكمل بروتوكول تسييل المحتوى البيئي Access Protocol مبلغ 1.2 مليون دولار أمريكي في جولة تمويل أوليةأعلن بروتوكول تسييل المحتوى البيئي الخاص بـ Solana، Access Protocol عن استكمال جولة تمويل أولية بقيمة 1.2 مليون دولار أمريكي، بمشاركة Sora Ventures وDV Ventures وCMS Holdings وDouble Peak Group ومستثمرين ملائكيين آخرين. وسيركز التمويل على تطوير Access v2، بالإضافة إلى منصتي Scribe وSketch.
- أغسطس ٠٣، ٢٠٢٣ ٩:٥٩ صArkham تطلق برنامج Arkham API التجريبي لتزويد أعضاء المجتمع بالوصول إلى API الخاص بهاأعلنت Odaily Planet Daily News Arkham ، وهي منصة تحليل ذكية مشفرة ، على Twitter إطلاق البرنامج التجريبي Arkham API ، الذي يوفر وصولاً إلى واجهة برمجة التطبيقات لأفراد المجتمع ويسمح للمستخدمين بالوصول إلى نفس واجهة برمجة التطبيقات التي يستخدمها Arkham لتوفير البيانات للمنصة. توفر Arkham API وصولاً مباشرًا للاستعلام إلى Ultra للمستخدمين المتقدمين لتخصيص تدفقات البيانات ودمجها في أنظمتهم الخاصة. Ultra هو محرك مطابق لعنوان الملكية يقوم بتشغيل منصة Arkham من خلال ربط عناوين blockchain بكيانات العالم الحقيقي. من خلال واجهة برمجة التطبيقات ، يمكن للمستخدمين كتابة استعلامات SQL مخصصة للوصول إلى قوائم علامات Arkham وكذلك سجل المعاملات وبيانات الرصيد التاريخية للعناوين والكيانات. يمكن للمستخدمين الآن إرسال طلبات للوصول إلى واجهة برمجة التطبيقات.
- مايو ١٩، ٢٠٢٣ ١١:٠٥ ص.SWOOSH:数字运动鞋系列「Our Force 1」的 General Access 销售推迟至 5 月 24 日耐克旗下 Web3 可穿戴设备平台.SWOOSH 宣布,其数字运动鞋系列「Our Force 1」由于在 First Access 销售阶段遇到了意外的流量高峰,因此「General Access」销售将推迟到 5 月 24 日。.SWOOSH 称其网站没有为 First Access 销售的流量激增做好准备,目前技术团队正在处理相关问题并将扩大网站容量增加负载支持。Foresight News 此前消息,.SWOOSH 于 5 月 17 日表示,由于技术问题,Our Force 1」的 First Access 销售延长至北京时间 5 月 18 日 14:59,原定于 5 月 18 日 00:00 的 General Access 销售将被推迟。
- أبريل ١٥، ٢٠٢٣ ١:٢٥ متعلن Sui عن برنامج SUI Token Community Accessأعلنت Sui عن خطة وصول مجتمع SUI token token. لن يتم إسقاط رموز SUI من الجو ، ولكنها ستوفر للداعمين حق الشراء. تشمل المشتريات المؤهلة الفائزين في مسابقة Capy Holidays خلال الجولة الأولى ، وبعض أعضاء منظمة Builder Houses وغيرها من الأحداث الرئيسية ، وبعض المشاركين من المجتمع. لم تفصح سوي عن معايير الدخول التفصيلية. بالإضافة إلى ذلك ، تدعم SUI عمليات الشراء عبر OKX و KuCoin ، ولكنها لن تكون مفتوحة لمواطني الولايات المتحدة أو المقيمين فيها.
- فبراير ٠٢، ٢٠٢٣ ٥:٥٣ ملن يدعم Twitter الوصول المجاني إلى Twitter API اعتبارًا من 9 فبرايرأعلن Twitter أنه اعتبارًا من 9 فبراير ، لن يدعم الوصول المجاني إلى Twitter API ، بما في ذلك الإصداران 2 و v1.1 ، وسيوفر طبقة أساسية مدفوعة ، لم يتم الإعلان عن معيار الشحن المحدد بعد. تتجاوز رسوم واجهة برمجة التطبيقات الخاصة بمؤسسة Twitter مليون دولار سنويًا.
- ديسمبر ١٤، ٢٠٢٢ ١:٣٨ متقدم MetaMask Institutional وصولاً برمجيًا للمؤسسات ، مما يمنح المؤسسات وصولاً مباشرًا إلى Web3 عبر واجهة برمجة التطبيقاتحل MetaMask المؤسسي أطلق MetaMask المؤسساتي (MMI) الوصول البرمجي للمؤسسات. سيسمح الوصول البرمجي للمؤسسات بالاتصال بـ Web3 من خلال واجهة برمجة التطبيقات الخاصة بهم ، وسيمكنهم من إنشاء نصوص لإكمال استراتيجيات التنفيذ المعقدة على بروتوكولات DeFi المختلفة ، وبناء وتخصيص و نصوص آلية لتسريع إنتاج المعاملات وتأكيدها وتوقيعها. يجب على المنظمات التي ترغب في استخدام الوصول الآلي إلى MMI التسجيل في MMI والعمل مع أحد شركائها المستضيفين ، وسيحتاجون إلى الوصول إلى "رمز التحديث المميز" الذي يوفره مضيفهم. "رمز التحديث" هو رمز ويب JSON ، وهو في الأساس طريقة مدمجة وآمنة وسريعة لتبادل المعلومات والمصادقة عليها بين طرفين. في ملحق مستعرض MMI ، تتم المصادقة داخل واجهة المستخدم ؛ عند الوصول إلى MMI برمجيًا ، يلزم وجود رمز تحديث لتجاوز هذا التفاعل. تتيح ميزة الوصول البرمجي الخاصة بـ MMI للمؤسسات التنفيذ برمجيًا عبر أمناء حفظ متعددين ، بدلاً من الاضطرار إلى الاتصال بكل أمين حفظ على حدة ، يمكن للمؤسسة ببساطة الاتصال بـ SDK موحد وإنشاء معاملات عبر جميع أمناء الحفظ الذين يختارونهم.


















